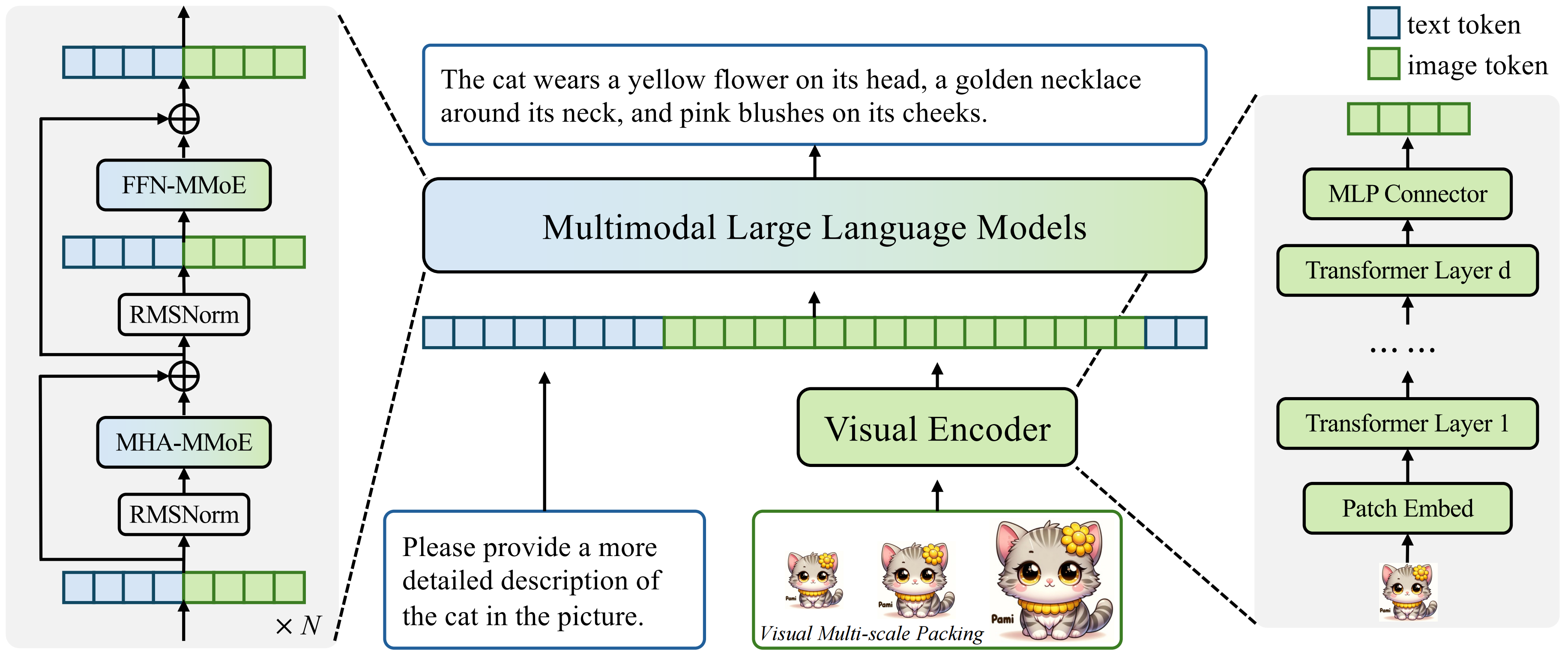
核心洞见
我们对原生 MLLM 的设计和扩展属性进行了系统性研究,得出了指导 NaViL 设计的五个关键结论:
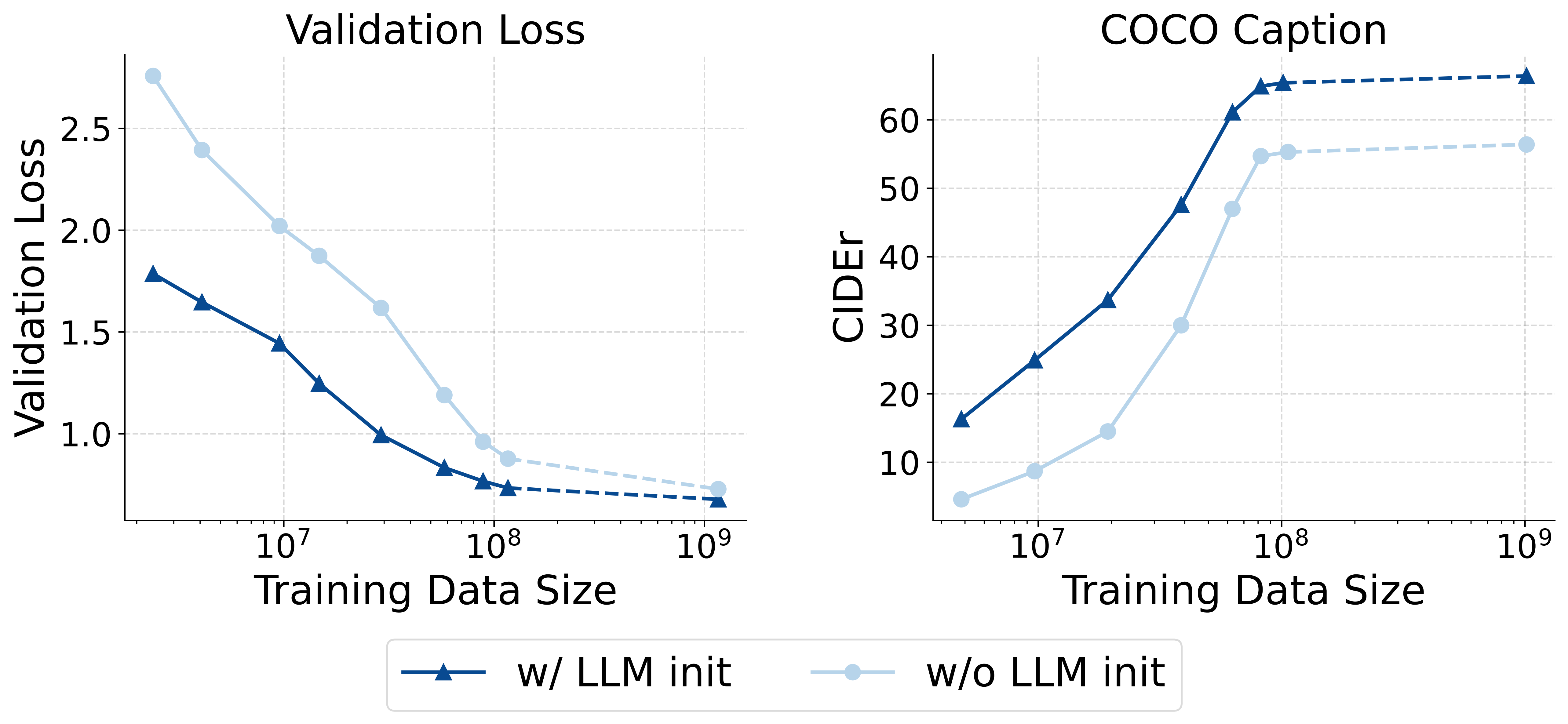
1. 大语言模型(LLM)的初始化至关重要
从一个预训练的 LLM 初始化模型,能显著加速多模态训练的收敛。即使拥有大量多模态数据,其性能通常也优于从零开始训练。
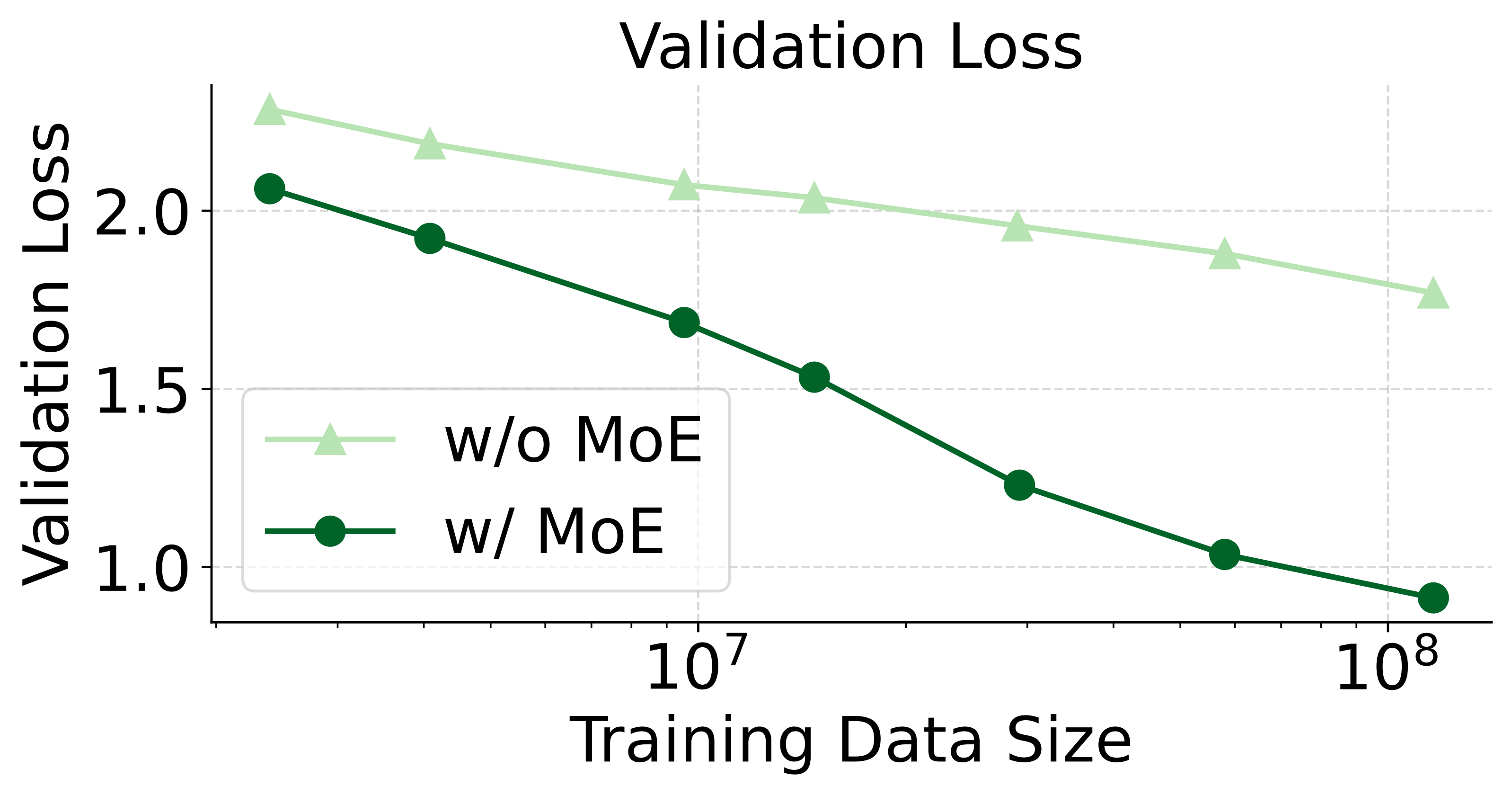
2. 混合专家(MoE)架构行之有效
混合专家(MoE)架构可以在不增加推理成本(激活参数量)的情况下,显著增强模型处理异构数据的能力并提升整体性能。我们发现,为注意力机制和前馈网络(FFN)同时引入模态特定的专家能产生最佳效果。
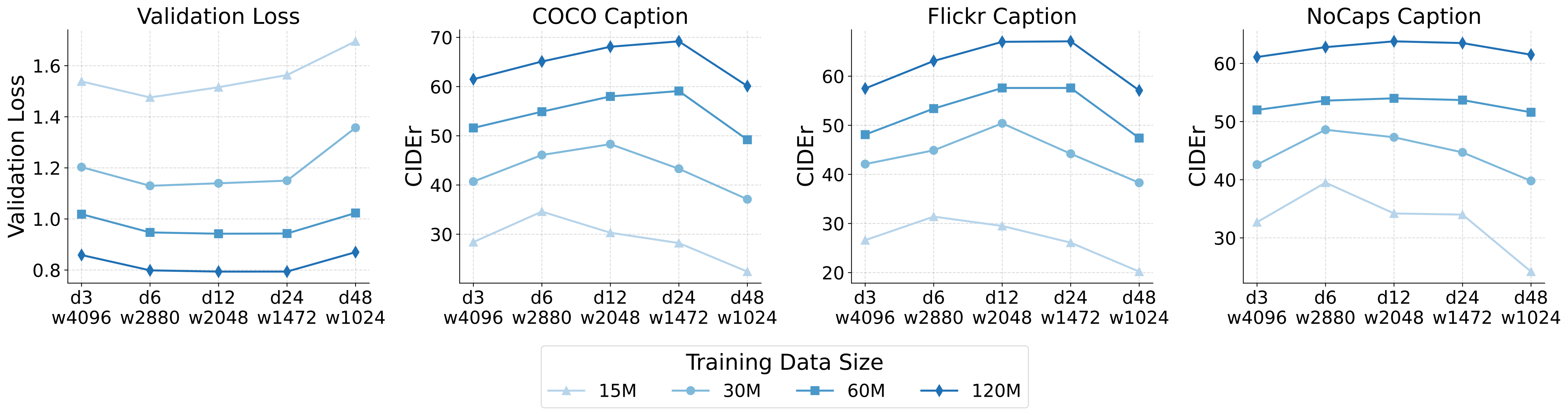
3. 视觉编码器架构的灵活性
在给定的参数预算下,视觉编码器的性能在广泛的深度和宽度配置中都接近最优。较浅的编码器在训练早期收敛更快,而较深的编码器在数据更多时表现略好。
4. 非对称的扩展效应
扩展 LLM 的规模能够持续提升多模态性能,这遵循了传统的语言模型扩展法则。然而,扩展视觉编码器带来的收益会递减,其性能上限受到 LLM 能力的制约。
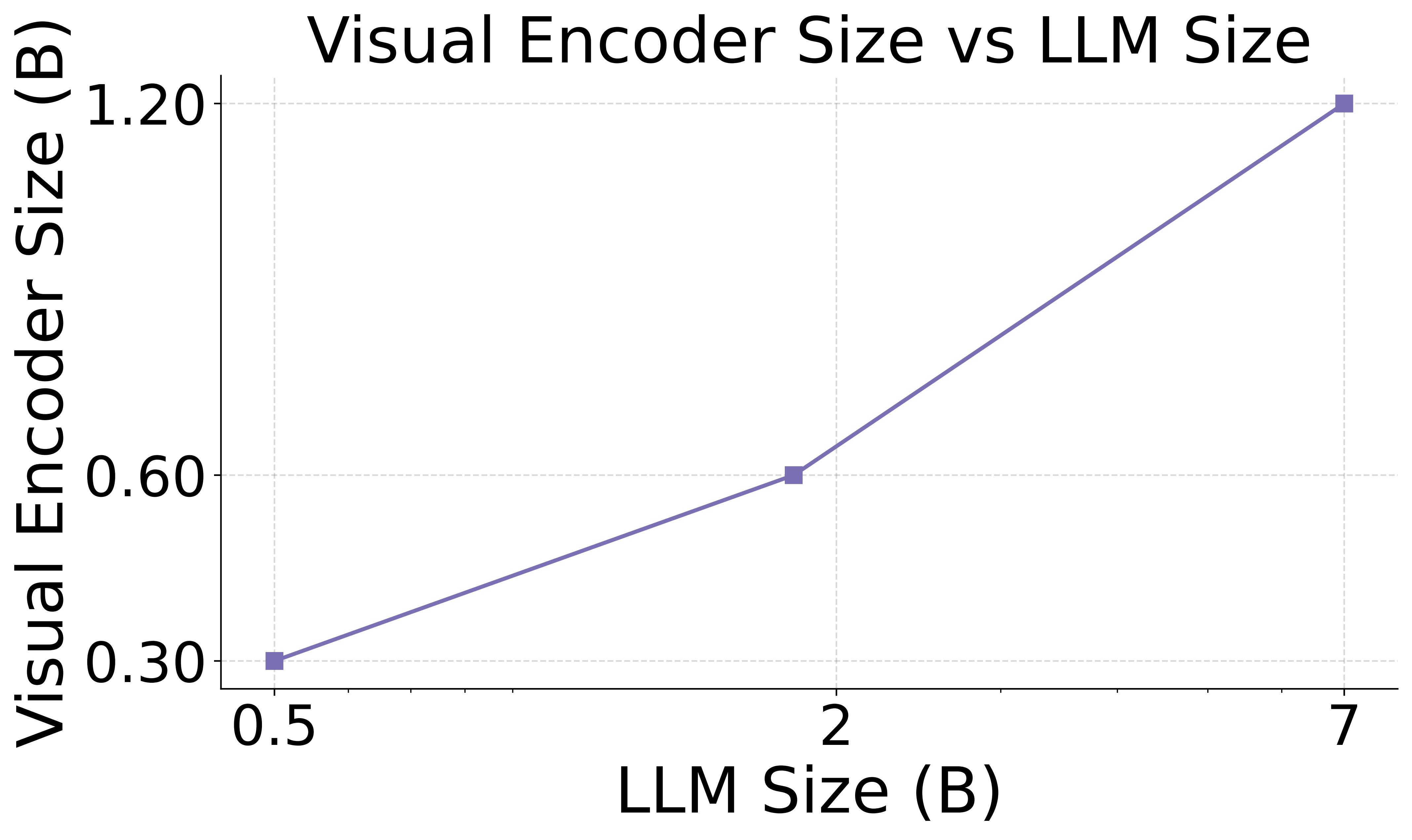
5. 视觉与语言的联合扩展法则
我们的研究首次揭示:视觉编码器的最优规模与 LLM 的规模在对数尺度上成正比。这意味着它们应当被联合扩展,同时也凸显了现有组合式 MLLM 将固定大小的视觉编码器与不同大小的 LLM 配对的次优性。