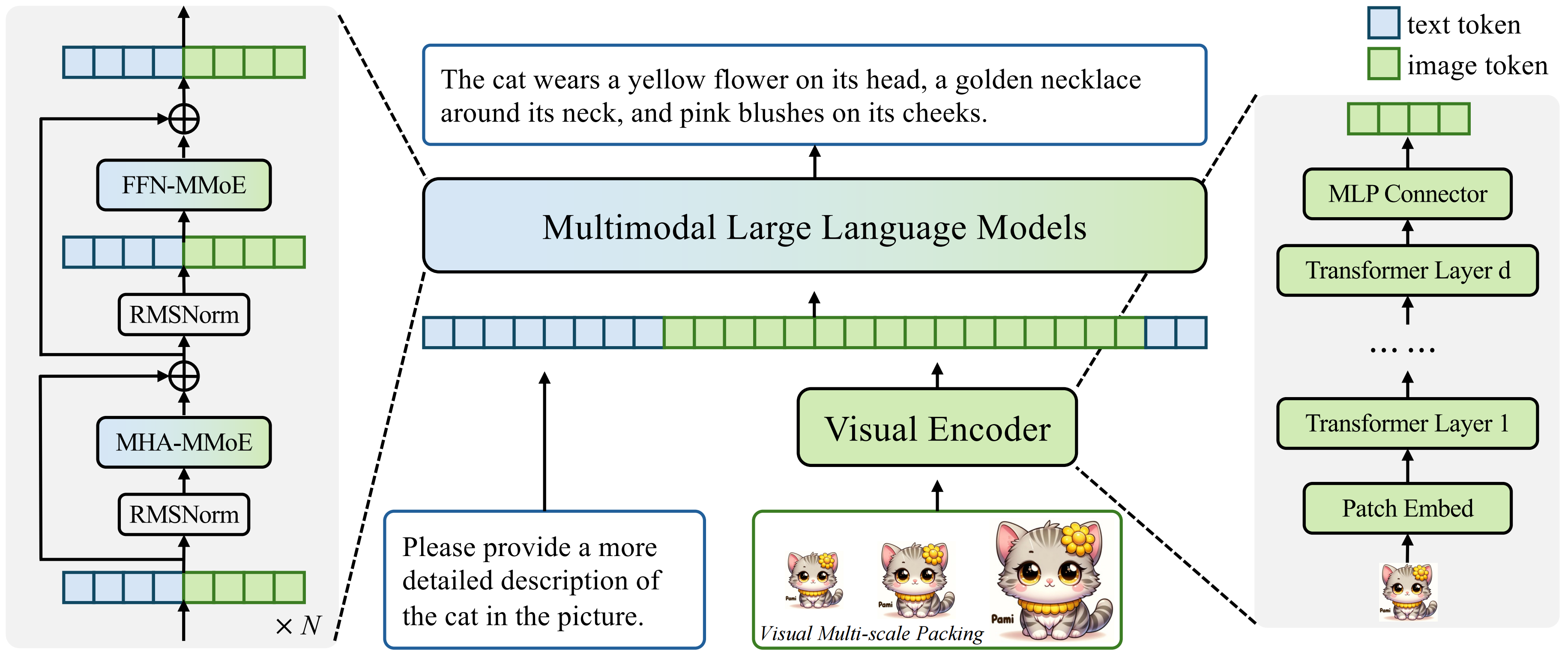
Core Insights
We conducted a systematic study on the design and scaling properties of native MLLMs, leading to five key conclusions that guided the design of NaViL:
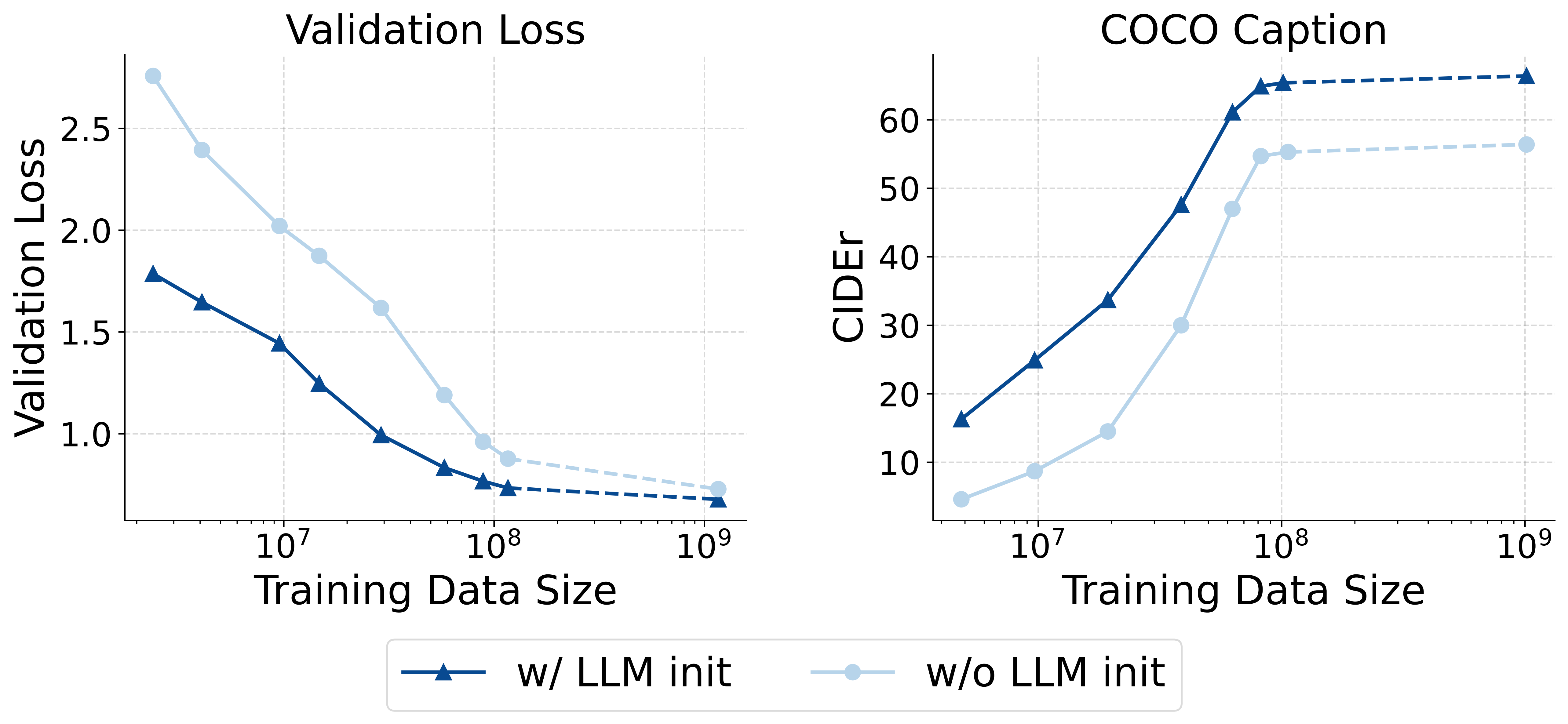
1. LLM Initialization is Crucial
Initializing the model from a pre-trained LLM significantly accelerates the convergence of multimodal training. Its performance is generally superior to training from scratch, even with a large amount of multimodal data.
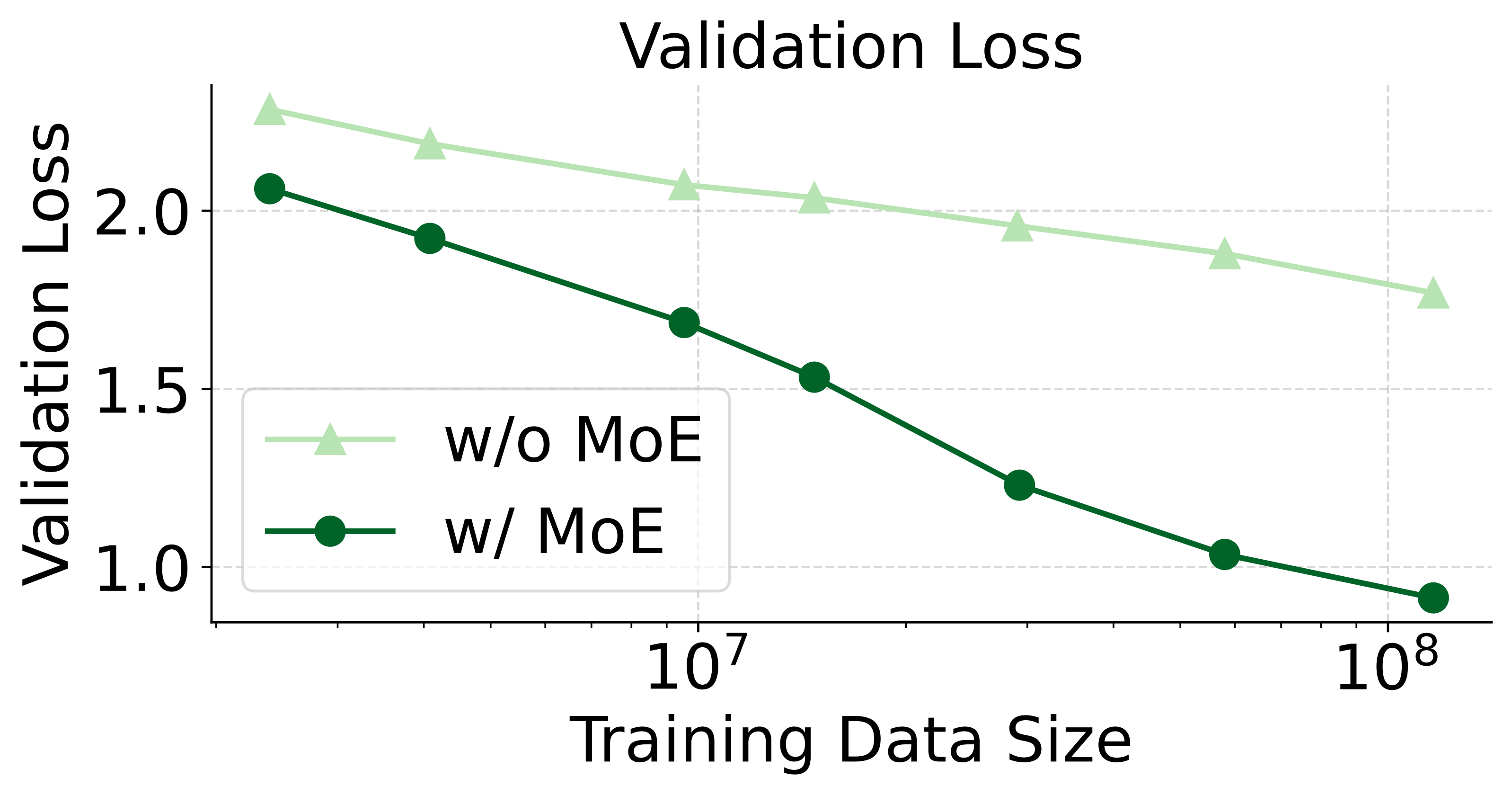
2. MoE Architecture is Effective
The Mixture-of-Experts (MoE) architecture can significantly enhance the model's ability to process heterogeneous data and improve overall performance without increasing inference costs (activated parameters). We found that introducing modality-specific experts for both attention and feed-forward networks (FFN) yields the best results.
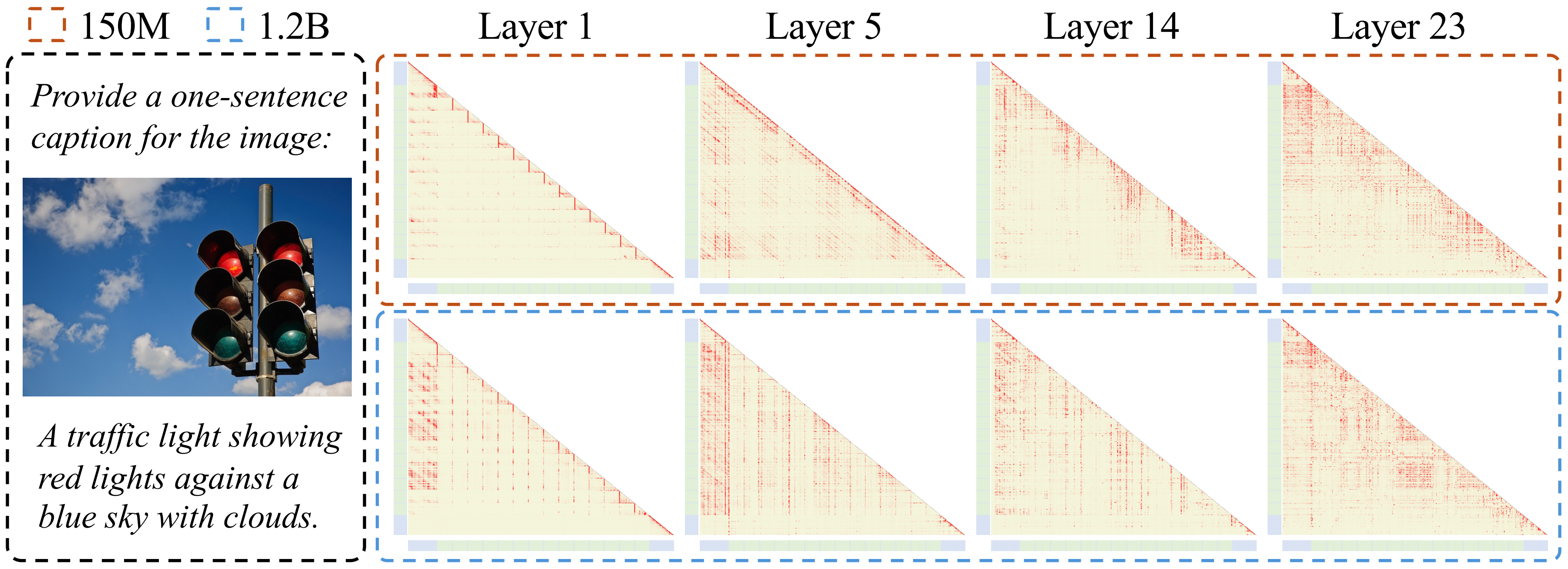
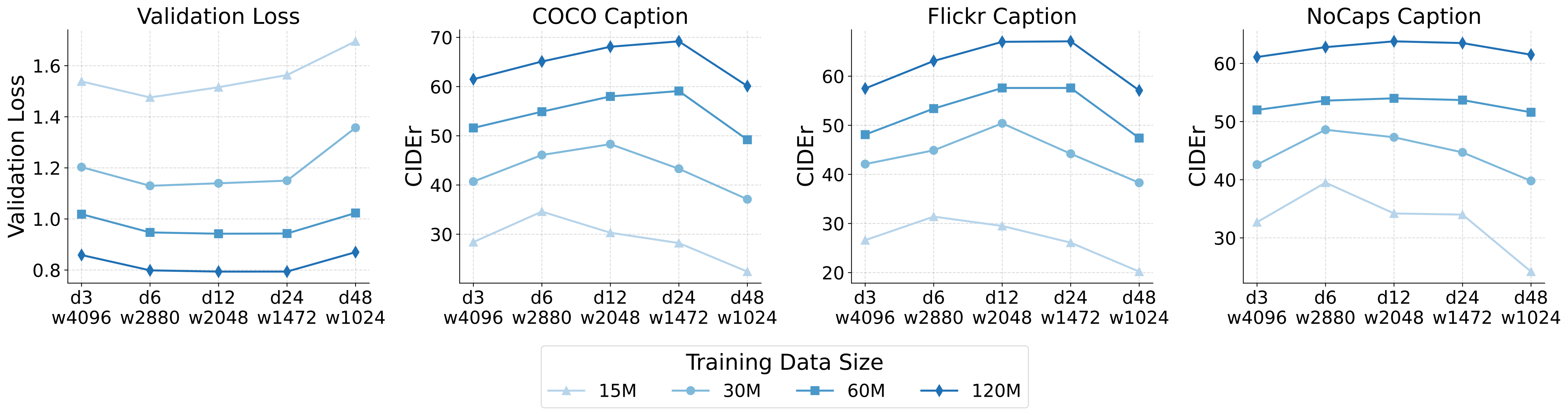
3. Flexibility of Visual Encoder Architecture
For a given parameter budget, the performance of the visual encoder is nearly optimal across a wide range of depth and width configurations. Shallower encoders converge faster in the early stages of training, while deeper encoders perform slightly better with more data.
4. Asymmetric Scaling Effects
Scaling up the LLM consistently improves multimodal performance, following traditional language model scaling laws. However, the benefits of scaling the visual encoder diminish, with its performance ceiling being constrained by the LLM's capacity.
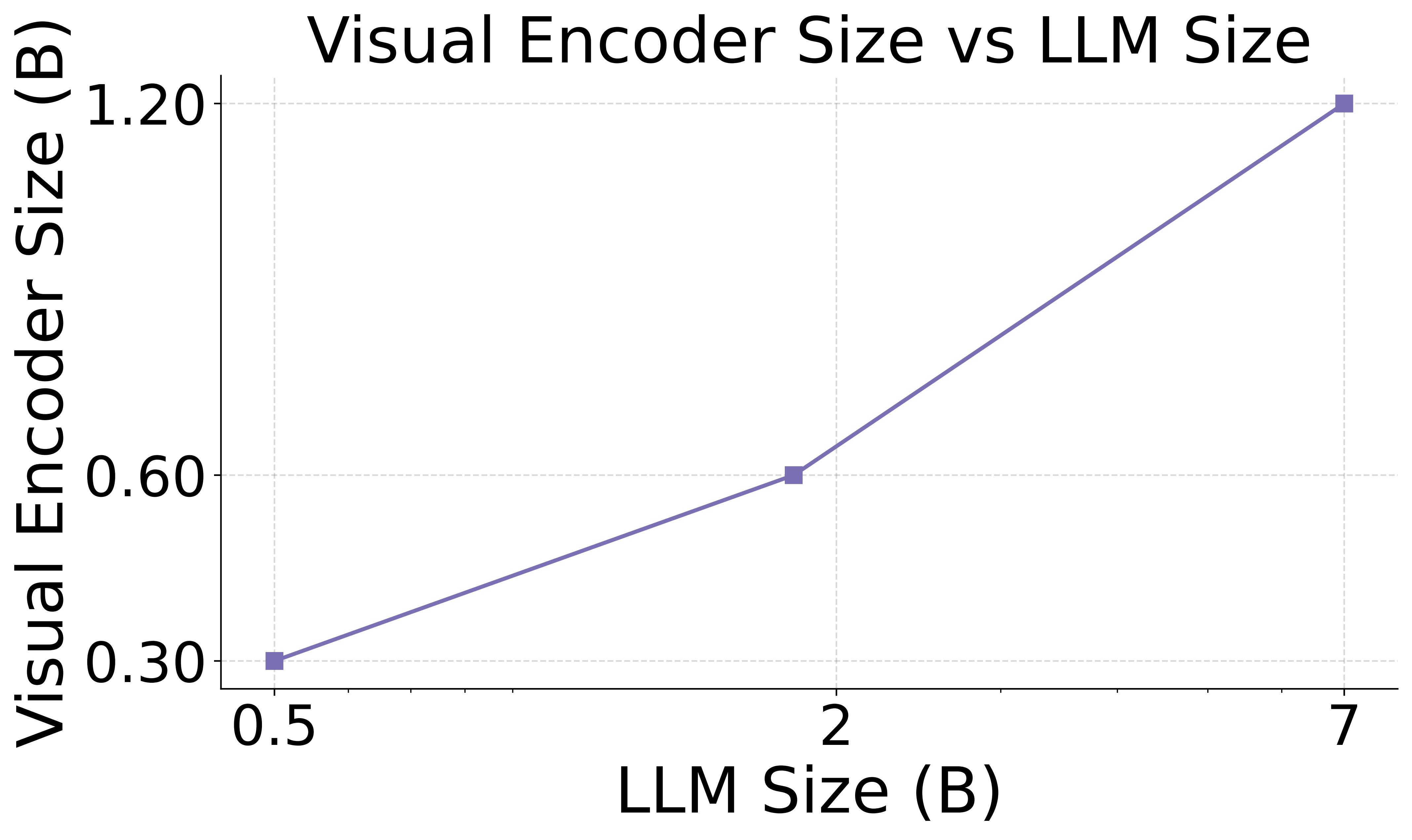
5. Joint Scaling Law for Vision and Language
Our research reveals for the first time that the optimal scale of the visual encoder is directly proportional to the scale of the LLM on a logarithmic scale. This implies that they should be scaled jointly and highlights the sub-optimality of existing compositional MLLMs that pair a fixed-size visual encoder with LLMs of different sizes.