InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
CVPR 2024 (Oral)
Abstract
The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models.
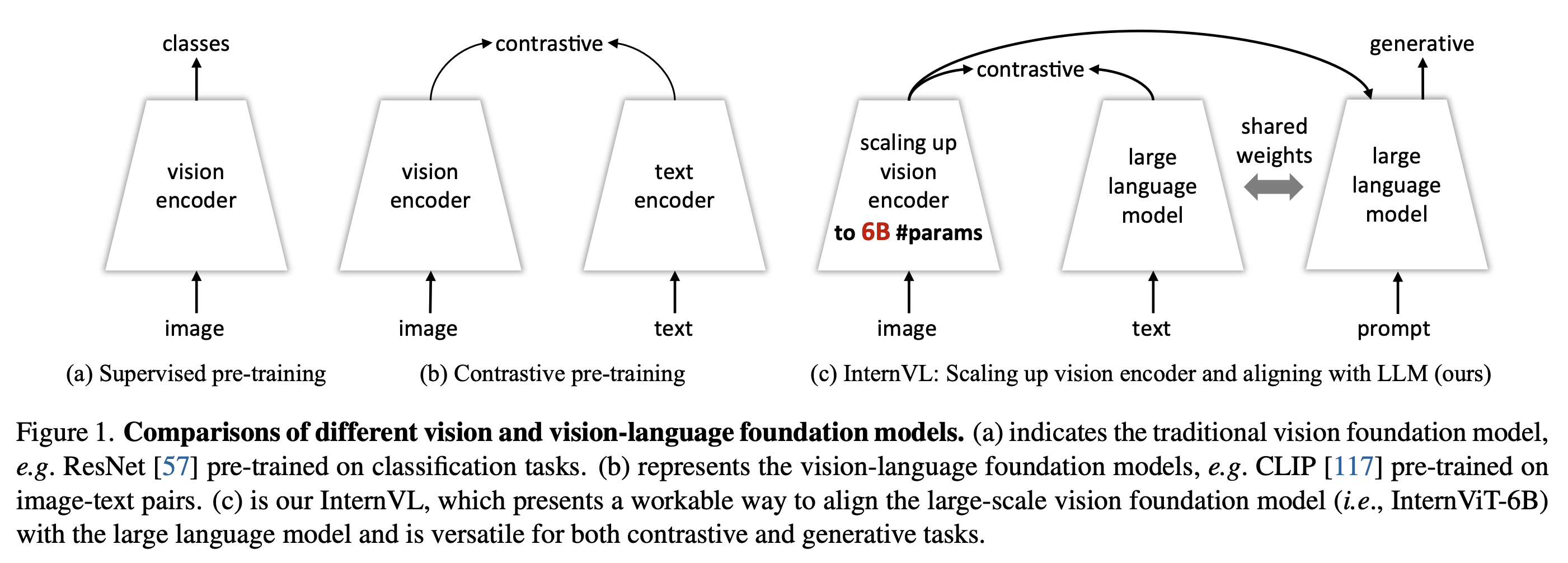
Scaling up Vision Foundation Models
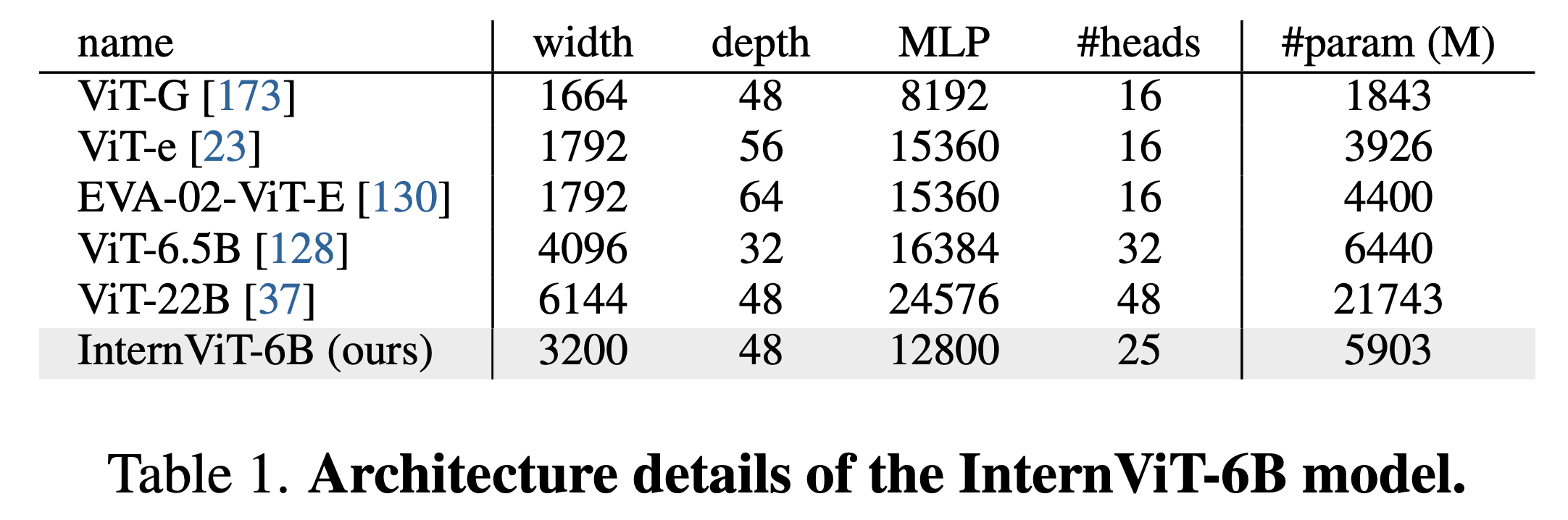
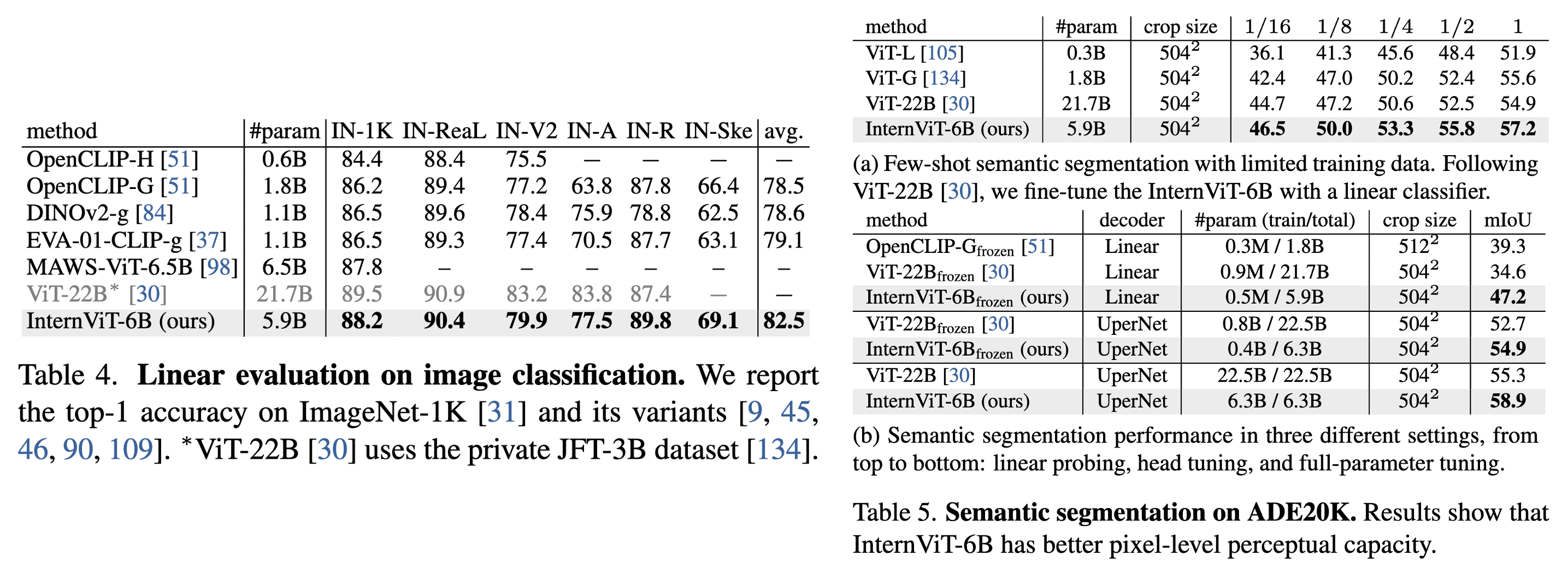
We implement the vision encoder of InternVL (i.e., InternViT-6B) with vanilla vision transformer (ViT). To match the scale of LLMs, we scale up the vision encoder to 6 billion parameters, resulting in the InternViT-6B model.
To obtain a good trade-off between accuracy, speed, and stability, we conduct a hyperparameter search for InternViT-6B.
We vary the model depth within {32, 48, 64, 80}, the head dimension within {64, 128}, and the MLP ratio within {4, 8}. The model width and the head number are calculated based on the given model scale and other hyperparameters.
We employ contrastive learning on a 100M subset of the LAION-en dataset to measure the accuracy, speed, and stability of InternViT-6B variants with different configurations.
We report the following findings:
- (1) Speed. For different model settings, when computation is not saturated, the models with smaller depths exhibit faster speed per image. However, as the GPU computation is fully utilized, the speed difference becomes negligible;
- (2) Accuracy. With the same number of parameters, the depth, head dimension, and MLP ratio have little impact on the performance. Based on these findings, we identified the most stable configuration for our final model, as shown in the following table.
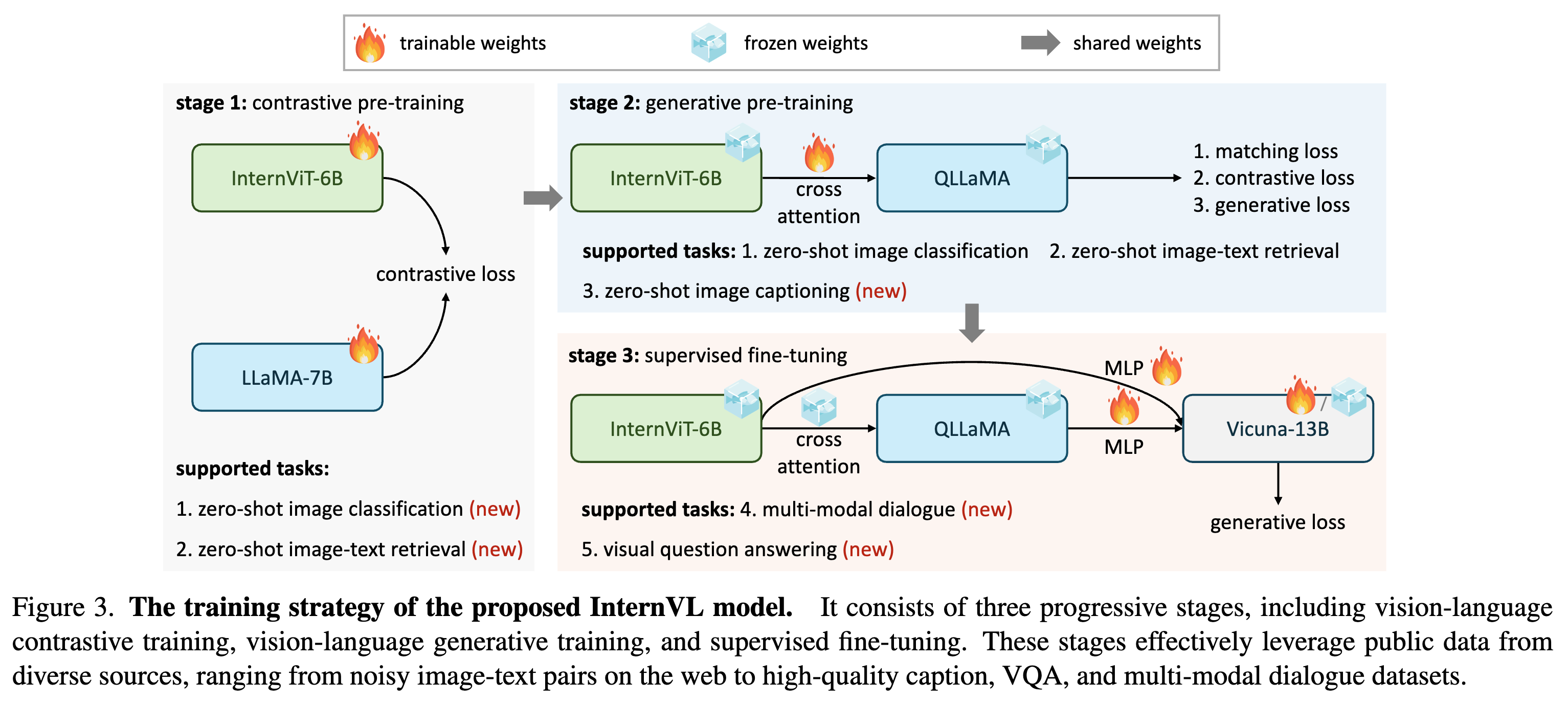
Aligning for Generic Visual-Linguistic Tasks
As shown in Figure 3, the training of InternVL consists of three progressive stages, including vision-language contrastive training, vision-language generative training, and
supervised fine-tuning. These stages effectively leverage public data from diverse soursota.pngces, ranging from noisy imagetext pairs on the web to high-quality caption, VQA, and multi-modal dialogue datasets.
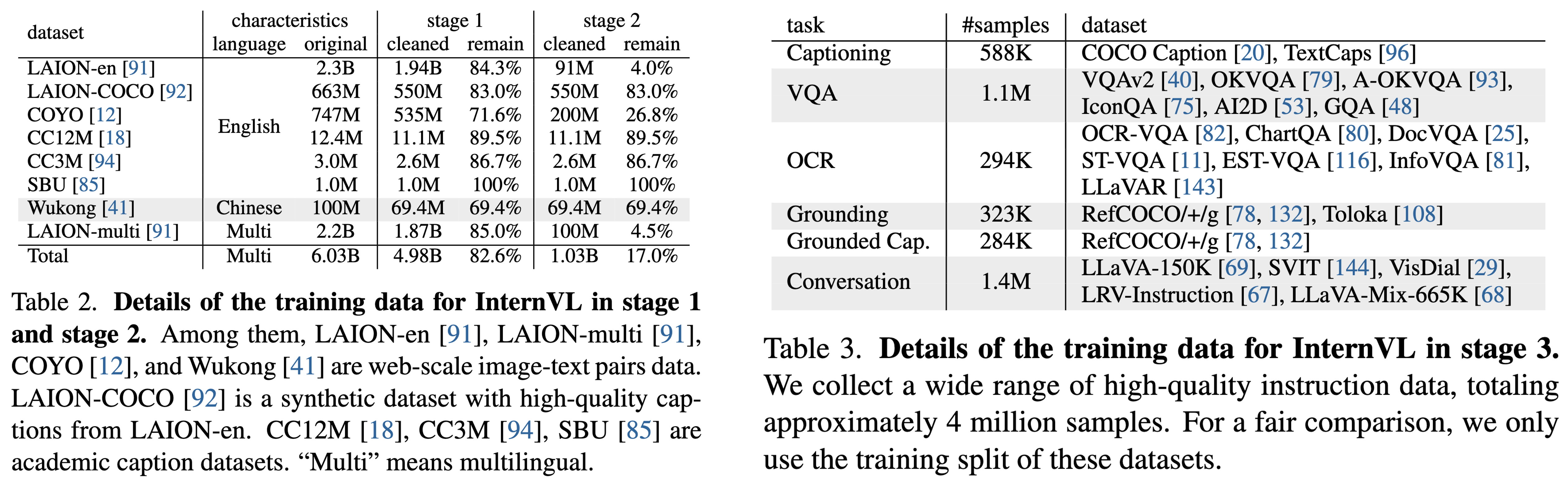
- Vision-Language Contrastive Training. In the first stage, we conduct contrastive learning to align InternViT-6B with a multilingual LLaMA-7B on web-scale, noisy imagetext pairs. The data are all publicly available and comprise multilingual content, including LAION-en, LAION-multi, LAION-COCO, COYO, Wukong, etc. We use the combination of these datasets and filter out some extremely low-quality data to train our model. As summarized in Table 2, the original dataset contains 6.03 billion image-text pairs, and 4.98 billion remains after cleaning.
- Vision-Language Generative Training. In the second stage of training, we connect InternViT-6B with QLLaMA and adopt a generative training strategy. Specifically, QLLaMA inherits the weights of LLaMA-7B in the first stage. We keep both InternViT-6B and QLLaMA frozen and only train the newly added learnable queries and cross-attention layers with filtered, high-quality data. Table 2 summarizes the datasets for the second stage. It can be seen that we further filtered out data with low-quality captions, reducing it from 4.98 billion in the first stage to 1.03 billion.
- Supervised Fine-tuning. To demonstrate the benefits of InternVL in creating multi-modal dialogue systems, we connect it with an off-the-shelf LLM decoder (e.g., Vicuna or InternLM) through an MLP layer, and conduct supervised fine-tuning (SFT). As detailed in Table 3, we collect a wide range of high-quality instruction data, totaling approximately 4 million samples.
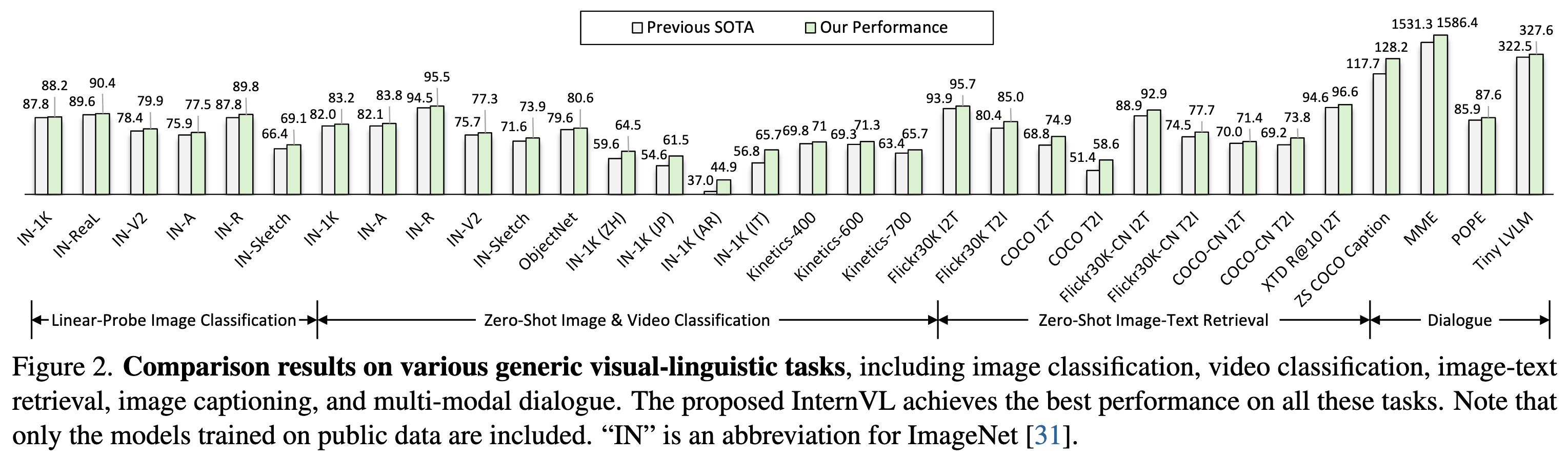
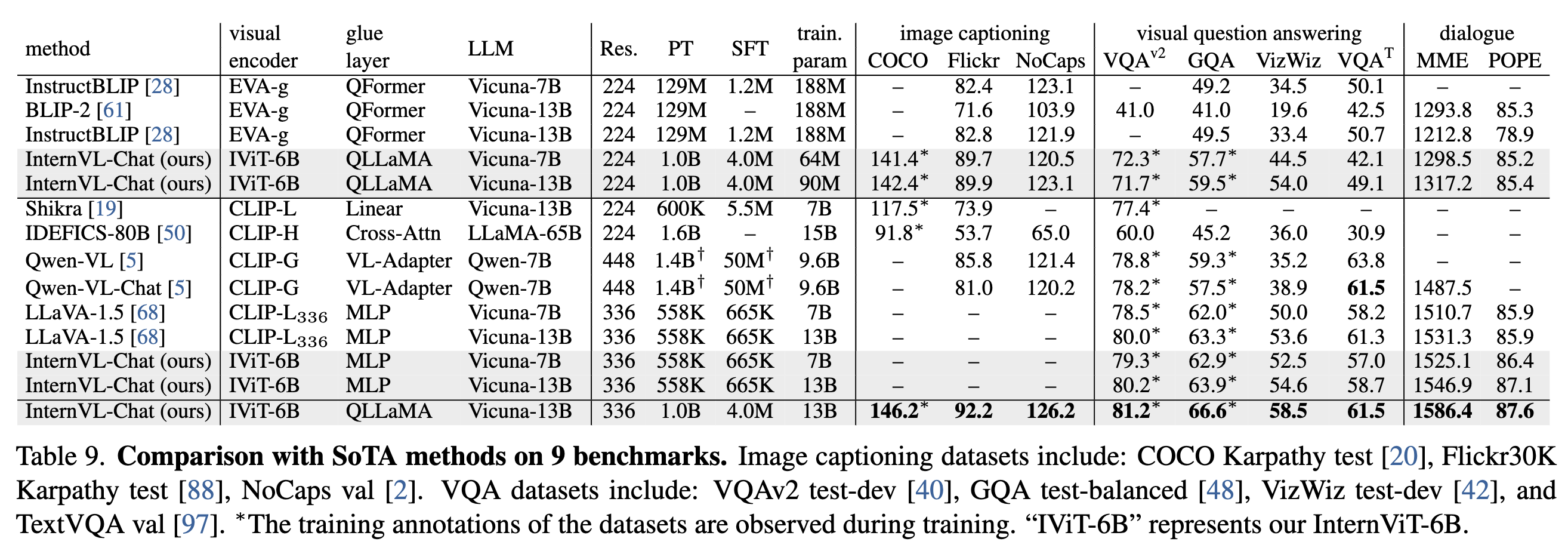
Performance
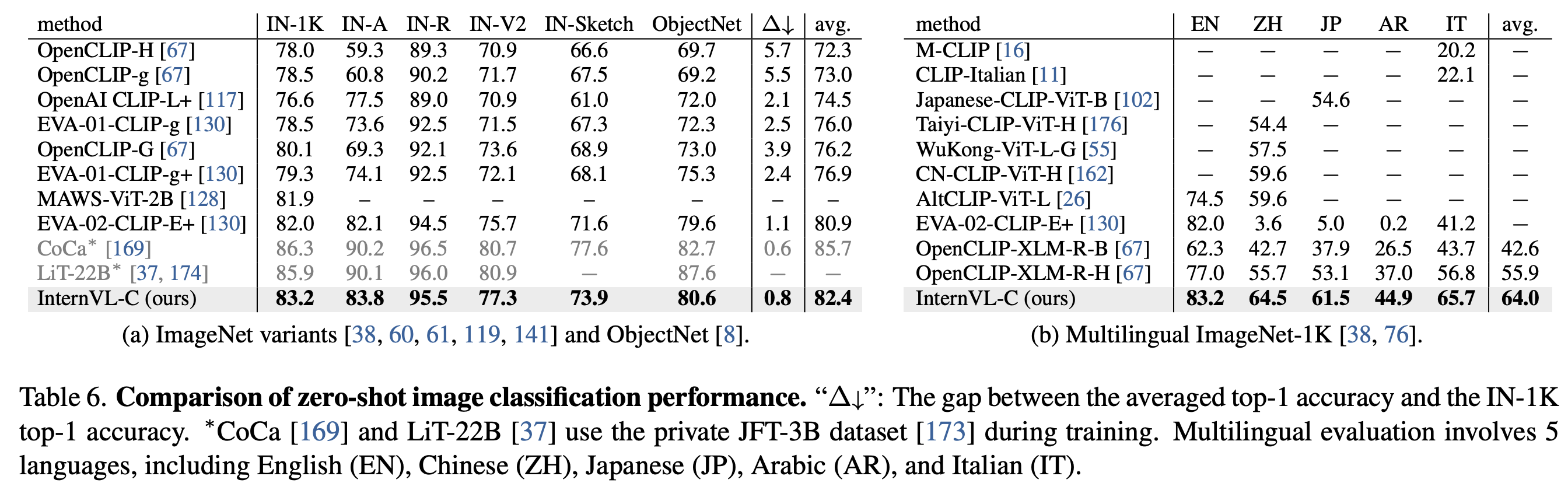
Visual Perception Benchmarks
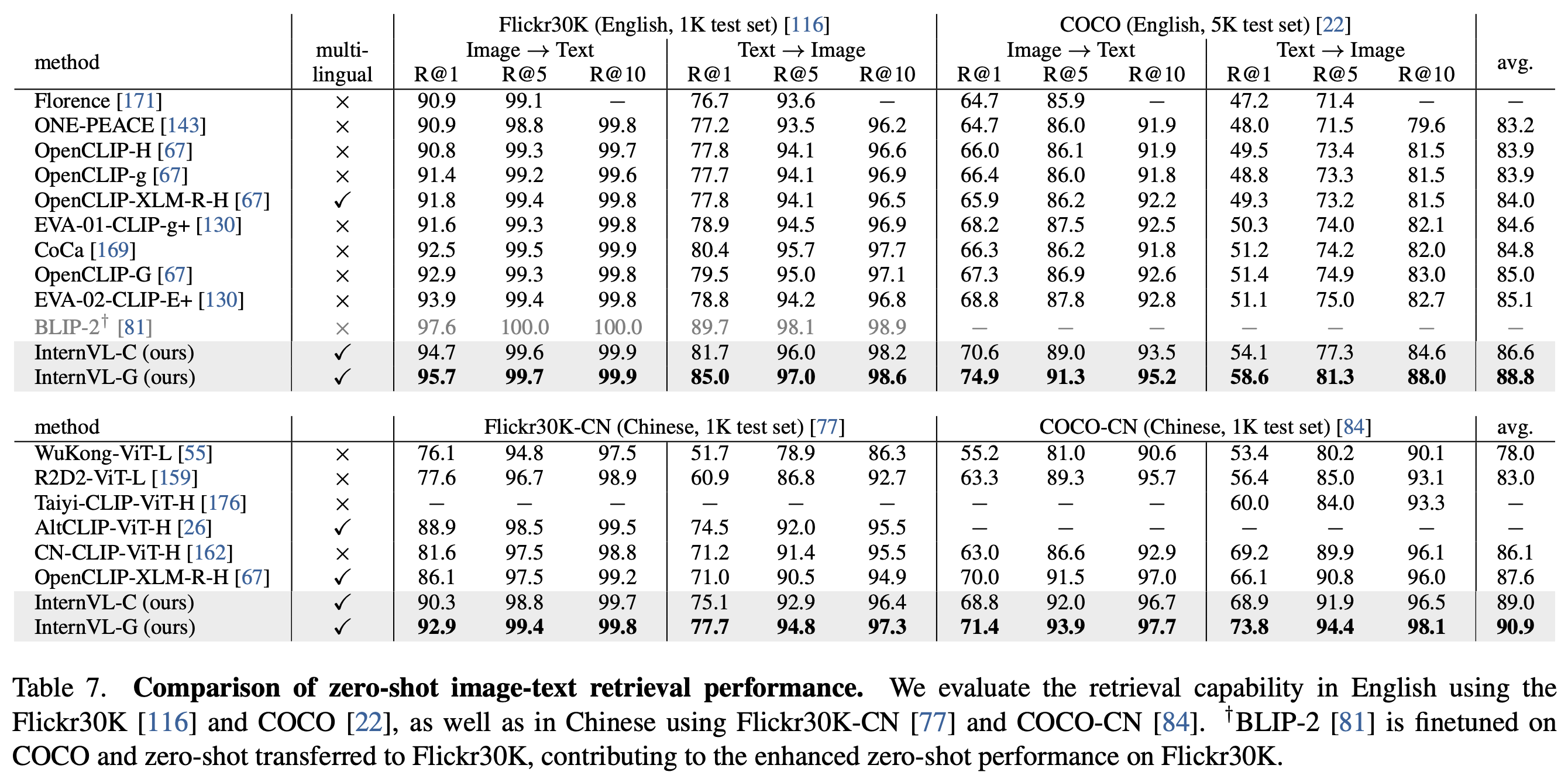
Vision-Language Benchmarks
Citation
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.